INTRO TO MACHINE LEARNING
A brief introduction to machine learning



- Data Science from different perspective
- What is Data Science
- Data Science Process
- Intro to Machine Learning
- Types of Machine Learning Systems
- Why Use Machine Learning?
- Reinforcement Learning
- Batch and Online Learning
- Instance-Based Versus Model-Based Learning
- Technologies

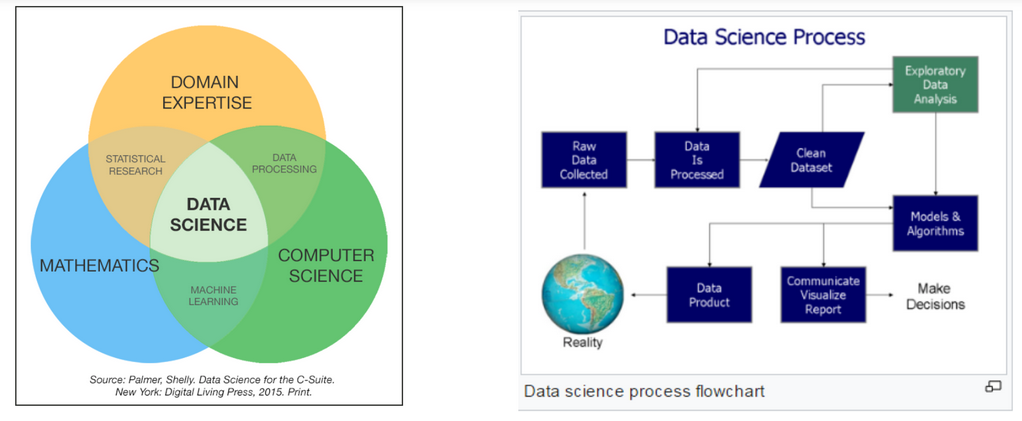
Data Science Process
The three components involved in data science are organising, packaging and delivering data.
The 3 step OPD Data Science Process
Step 1. Organise Data.
Organising data involves the physical storage and format of data and incorporated best practices in data management.
Step 2. Package Data.
Packaging data involves logically manipulating and joining the underlying raw data into a new representation and package.
Step 3. Deliver Data.
Delivering data involves ensuring that the message that the data has, is being accessed by those that need to hear it.

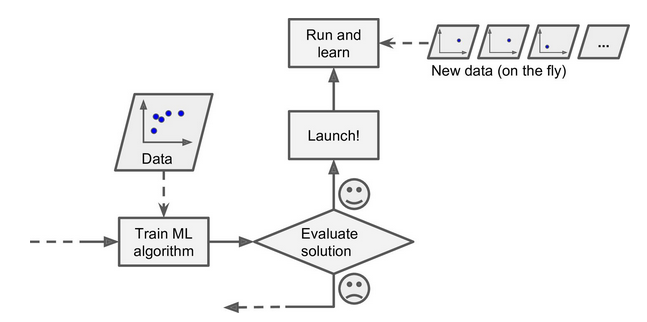
Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem.
Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
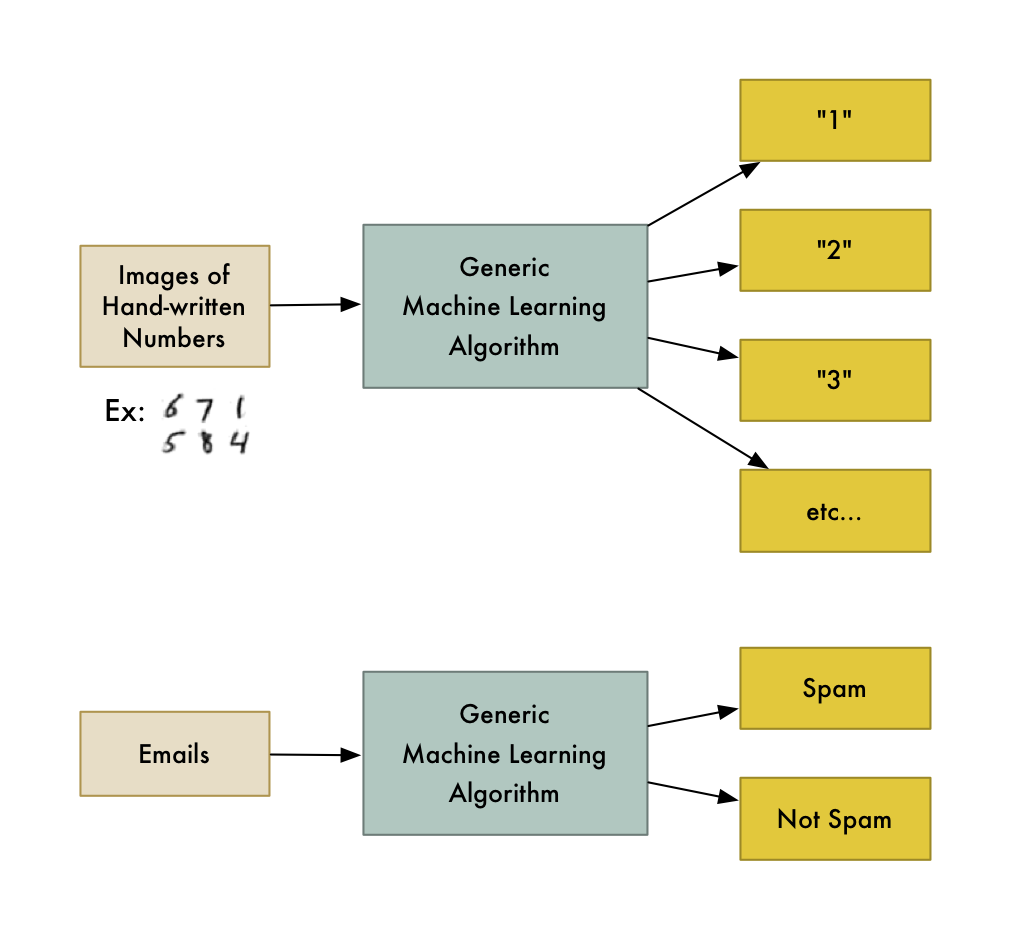
Types of Machine Learning Systems
There are so many different types of Machine Learning systems that it is useful to classify them in broad categories based on:
- Whether or not they are trained with human supervision (supervised, unsupervised, semisupervised, and Reinforcement Learning)
- Whether or not they can learn incrementally on the fly (online versus batch learning)
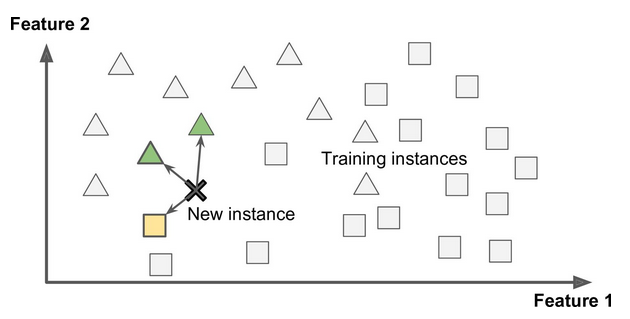
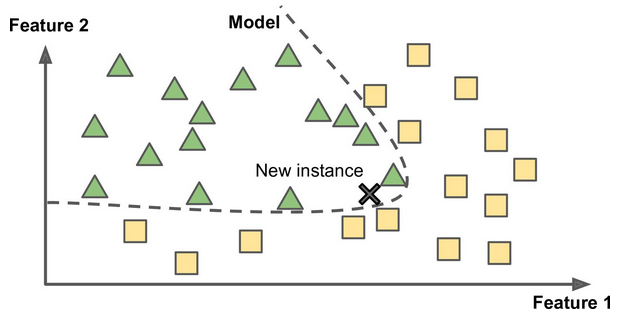
- Whether they work by simply comparing new data points to known data points, or instead detect patterns in the training data and build a predictive model, much like scientists do (instance-based versus model-based learning)
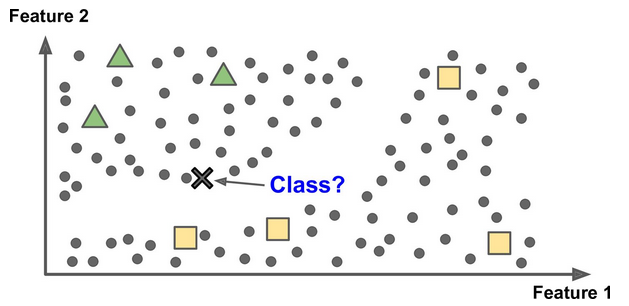
Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output. The goal is to approximate the mapping function so well that when you have new input data (x) that you can predict the output variables (Y) for that data.
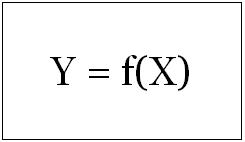
Supervised learning problems can be further grouped into regression and classification problems.
Classification:
A classification problem is when the output variable is a category, such as “red” or “blue” or “disease” and “no disease”.
Regression:
A regression problem is when the output variable is a real value, such as “rupees” or “weight”.
In Machine Learning an attribute is a data type (e.g., “Mileage”), while a feature has several meanings depending on the context, but generally means an attribute plus its value (e.g., “Mileage = 15,000”). Many people use the words attribute and feature interchangeably, though.
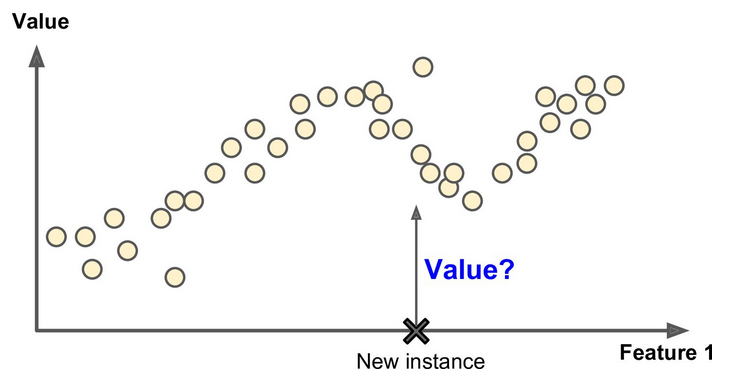
Unsupervised learning is where you only have input data (X) and no corresponding output variables.
The goal for unsupervised learning is to model the underlying structure or distribution in the data in order to learn more about the data.
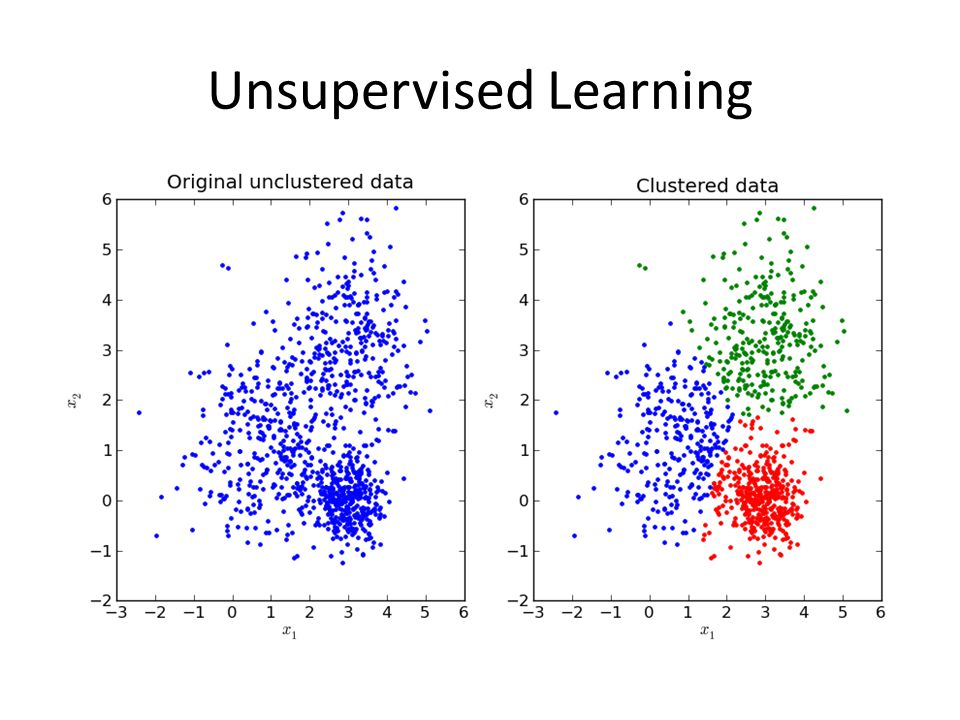
Unsupervised learning problems can be further grouped into clustering and association problems.
Clustering:
A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
Association:
An association rule learning problem is where you want to discover rules that describe large portions of your data, such as people that buy X also tend to buy Y.
Supervised Vs Unsupervised
-
Supervised learning
- Trying to predict a specific quantity.
- Have training examples with labels.
- Cam measure accuracy directly
-
Unsupervised learning
- Trying to understand the data
- Looking for structures or unusual patterns
- Not looking for something specific (supervised)
- Does no require labelled data
- Evaluation, usually indirect or qualitative
-
Semi Supervised learning
- Using unsupervised methods to improve supervised algorithms.
- Usually few labelled examples + lot of unlabelled examples
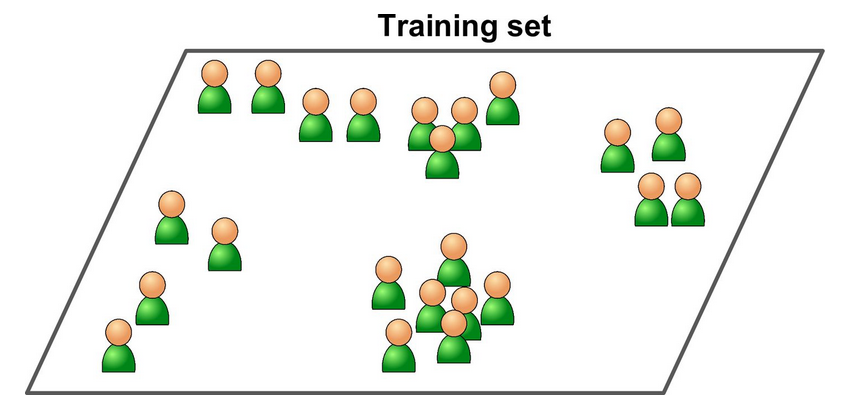
Some algorithms can deal with partially labeled training data, usually a lot of unlabeled data and a little bit of labeled data.
Some photo-hosting services, such as Google Photos, are good examples of this.
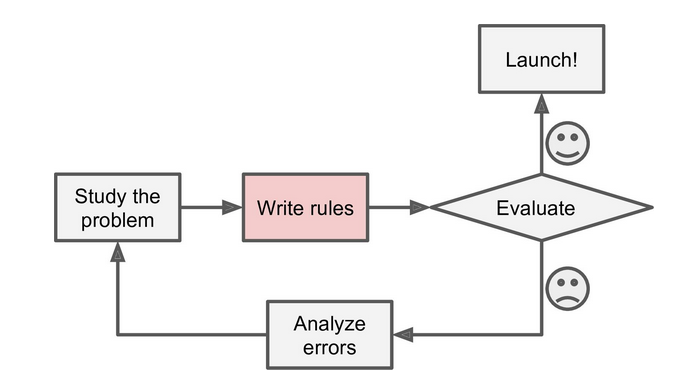
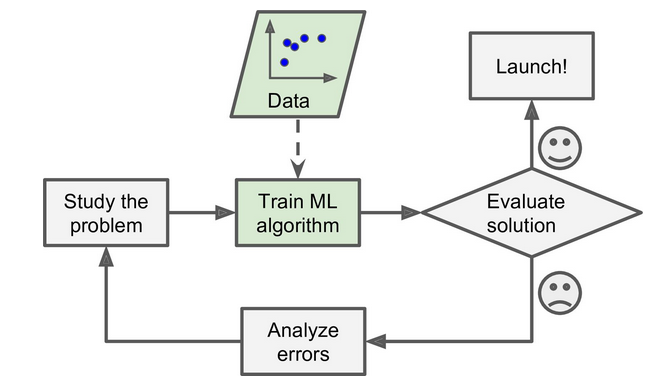
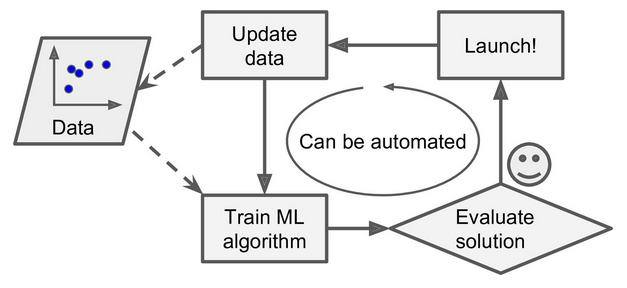
To summarize, Machine Learning is great for:
-
Problems for which existing solutions require a lot of hand-tuning or long lists of rules: one Machine Learning algorithm can often simplify code and perform better.
-
Complex problems for which there is no good solution at all using a traditional approach: the best Machine Learning techniques can find a solution.
- Fluctuating environments: a Machine Learning system can adapt to new data.
- Getting insights about complex problems and large amounts of data.
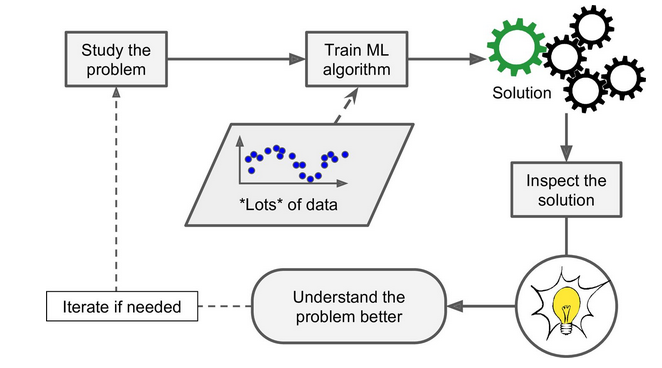
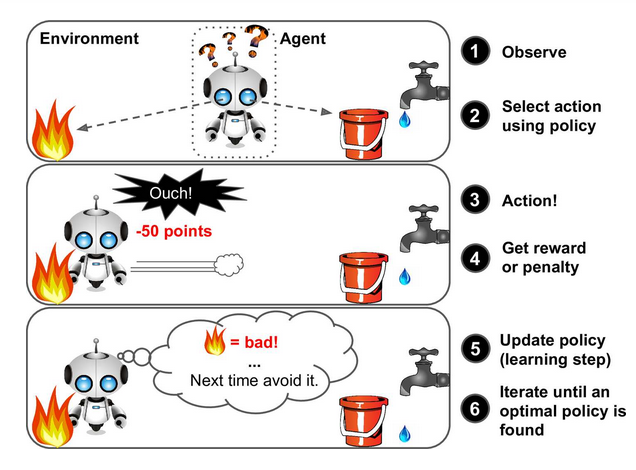
Reinforcement Learning is a very different beast. The learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards